
Bloom Filter – Part 4

As promised, this fourth article will discuss the implementation of the “scalable bloom filter.”
Following is the link to my earlier articles.
Bloom Filter – Part 1
Bloom Filter – Part 2
Bloom Filter – Part 3
In this article, you will learn to…
Scalability issue of a typical bloom filter.
How a scalable bloom filter addresses the scalability issue
Understand the workings of a scalable bloom filter.
Learn to code scalable bloom filters in Python.
Understand the logic of keeping the overall error rate of a scalable bloom filter under check.
Scalable Bloom filter
I encourage you to read the articles mentioned above. If you are unaware of the concept of a Bloom filter, these articles will give you the required baseline to understand this article. We start by understanding a scalable bloom filter.
A quick summary of Bloom Filter
A Bloom filter is a space-efficient, probabilistic data structure. It helps identify whether an element is available in a set. When we say probabilistic, it means that the element we are searching for “possibly exists in the set” or it “does not exist in the set.” There is no definitive answer. It provides a probability that an element may exist.
The main benefit of using this data structure is that it is fast and space-efficient. However, it comes with a trade-off of accuracy. Mathematical formulas are available to manage the probability of getting the wrong answers (False-positive). Please refer to the above articles for more details.
Scalability issue
One main disadvantage of a traditional bloom filter is its fixed size, defined at initialization. The size depends on the expected number of elements to add to the filter and the expected error rate. As a bloom filter reaches its capacity, the False-positive rate increases. And it is not possible to increase its size on the fly. To address this problem, scalable bloom filters were developed.
Working of scalable Bloom filter
A scalable bloom filter is a variant of a traditional bloom filter. It adjusts its size dynamically to accommodate additional elements and maintains the False-Positive rate.
It starts as a standard bloom filter. As the elements are added, the expected “False-Positive” rate is tracked. Once its threshold is reached, a scalable bloom filter adds a new filter to accommodate more elements and maintains the required “False-Positive” rate.
This is implemented by stacking a new filter on top of the existing one. Each filter can have its own set of hash functions and different sizes.
While searching for an element, all the filters in the stack are queried before it is marked as available or not. This can be more time-consuming than a traditional bloom filter.
Coding time
To implement a scalable bloom filter, I will reuse the code of the class BloomFilter, which I introduced in the article Bloom Filter — Part 2
I start with the list of hash functions we need for this implementation. Several hash functions are taken from the hashlib library of Python. I also used zlib for crc32 and mmh3 for hash128 function. All these are mentioned in the file For Article/Bloom Filter — Part 4/hashes.py. Finally, I created a list hash_functions that enlists all the hash functions from the different libraries.
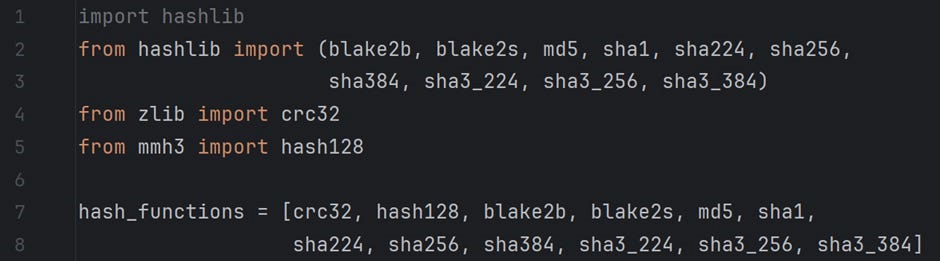
The file For Article/Bloom Filter — Part 4/measurements.py implements three functions. The following describes these functions.
get_bits_count — This function returns the size of a bit-array required to manage the required number of elements with the acceptable error rate of “False-Positive.” This function accepts two arguments, “expected_elements” and “error_rate.” The error rate ranges from 0 (0%) to 1 (100%).
get_hash_func_count — This function returns a number of hash functions we should use to manage the elements of a bloom filter with a given error rate of False-Positive. This function accepts two arguments, “bits count” — the size of the bit-array and “expected_elements” — the number of entries this bloom filter is expected to contain.
get_false_positive_probability — this function returns the probability (percentage) of getting a “False-Positive” at a given time. This function accepts three arguments, “hash_function_count” — the number of hash functions used in this bloom filter, “total_entries” — the number of elements added in the bloom filter at this point and “bloom_filter_size” — the bit-array size.
While creating a new bloom filter, we should know the expected number of elements we wish to add and the acceptable error rate of “False-Positive.”
One more file, For Article/Bloom Filter — Part 4/input_data.py, contains the data this program inserts and searches for. It contains three lists: marvel_characters, inserted into the data structure, and DC_characters, which we search for in the data structure. In addition, it contains two more lists with more characters. You can use these to play around as well.
The main implementation is in the file, For Article/Bloom Filter — Part 4/scalable_bloom_filter.py. This file contains two classes. First, I explain the class BloomFilter.
I have used bitarray library to implement the bit-array. It uses the functions I explained in the file measurements.py and hashes.py.
When an object of the class BloomFilter is created, it accepts three arguments:
expected_entries — is the number of entries this bloom filter will contain.
error_rate — is the acceptable error rate of “False-Positive.” Mentioned in percentages ranging from 0 (0%) — 1(100%)
load_threshold — This indicator triggers the creation of a new bloom filter when a certain percentage of bits is set to 1. It, too, is mentioned in percentage.

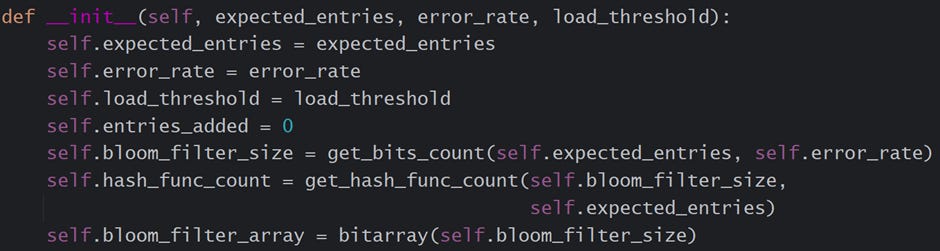
__init__() — The initialization function calculates the bit-array size and creates one. The following is an explanation of the class’s attributes.
expected_entries — stores the count of the total number of entries this data structure is expected to have. A user provides this input.
error_rate — is the acceptable error rate at which this data structure can operate. The value ranges from 0 (0%) to 1 (100%). A user provides this input.
load_threshold — indicates the threshold in the percentage of bits marked as “1”. Once the threshold is crossed, it indicates the class ScalableBloomFilte class to create a new BloomFilter object.
entries_added — is the count of entries added in this data structure at a given time. This value increments as and when a new value is added.
bloom_filter_size — is a calculated field. It is the number of bits a bit-array should have to support the “expected_entries” at a given “error_rate.”
hash_func_count — is a calculated field. It is the count of hash functions this data structure must use to support the “expected_entries” at a given “error_rate.” Note that this program limits the number of hash functions available to 12.
bloom_fliter_array — is the bit-array that contains all the data.
add_new_data — this function adds a new element to the bloom filter. It does this in three steps. The first step calculates all the indices for a given element. The function for this activity is get_bit_array_indices. The second step marks the bit-array with the value 1 for these indices. The function of this activity is update_filter_array. And finally, it increments the count of “entries_added.”
get_hash_digest — This function calculates the hash value for a given data element using a given hash function.
To generate an index, a hash function is applied to a data element. This returns a hash value. The hash value is then “modulo-ed” by the size of the bit-array (divide the hash value by the bit-array size using the modulo operator. This returns the reminder, which is an index of the bit-array to set the value to 1)
load_threshold_full — this function checks the number of bits set to 1 as and when the data elements are added and returns True when the number of bits set as 1 passes a certain threshold. This triggers the creation of a new bloom filter.
data_exist — This function checks the bloom filter for a given element. It starts with calculating the indices of the data value using the same set of hash functions used while inserting data into the data structure.
Every index is then checked in the bit array.
If any index value is 0, the function returns False, indicating that the data value does not exist.
Otherwise, the function returns True, indicating a data value in the data structure.
The last method is __str__(). This prints the details of a Bloom Filter object, which is useful while playing around with and debugging the code.
The second class implemented in the file is the ScalableBloomFilter. This class uses the class BloomFilter to implement a scalable Bloom filter.
When an object of the class ScalableBloomFilter is created, it accepts four arguments:
expected_entries — is the number of entries this bloom filter will contain.
error_rate — is the acceptable error rate of “False-Positive”. Mentioned in percentages ranging from 0 (0%) — 1(100%)
growth_factor — this value indicates the factor with which the size of a new bloom filter increases and the error rate decreases.
load_threshold — This indicator triggers the creation of a new bloom filter when a certain percentage of bits is set to 1. It, too, is mentioned in percentage.
When the first bloom filter is created, the three arguments (expected_entries, error_rate, and load_threshold) are passed to the class BloomFilter.

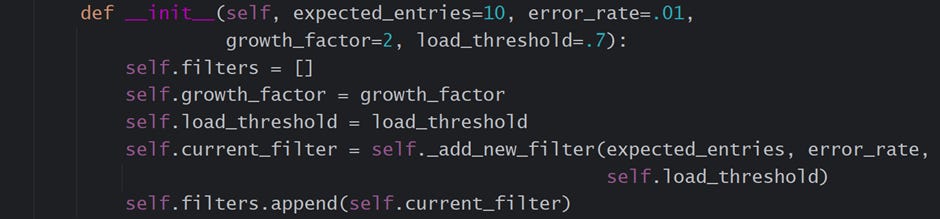
__init__() — The initialization function passes the request of creating a new Bloom filter to the class BloomFilter. Following is an explanation of the class’s attributes
filters — It is a list that maintains the various bloom filters. Each element of this list represents one bloom filter object.
growth_factor — indicates the factor with which the size of a new bloom filter increases and the error rate decreases. For example, if the first bloom filter has a bit-array size of 100 and an error rate of 10%, the subsequent bit-array will have 100 * 2 = 200 bits, and its error rate will be set to 10/2 = 5%.
load_threshold — indicates the threshold in the percentage of bits marked as “1”. Once the threshold of a bloom filter is crossed, the class creates a new BloomFilter object.
current_filter — represents a currently active bloom filter object. It is the most recent object of the class BloomFilter added to the list of filters.
The method load_threshold_full is a wrapper of the methods in the class BloomFilter.
add_new_data is a wrapper that adds a new element to the bloom filter. After adding a new data element, the function checks whether it is time to create a new bloom filter object.
ready_to_create_new_filter — This function does two checks. First, it checks whether the number of entries added so far (entries_added) is less than expected_entries. If entries_added equals expected_entries, a new bloom filter is required to keep the error_rate in check.
The second check checks whether the number of bits set as “1” exceeds a certain threshold, expressed in percentage.
I feel both checks are required. All the expected entries may have been added, yet the bloom filter has many bits that are still not set to “1.” This happens because the number of indices generated may overlap for a particular data element(s).

create_new_filter: This function resets the bit-array count by multiplying it by the growth_factor and the error_rate by dividing it by the growth_factor. This ensures that with each added bloom filter, the overall error rate of the scalable bloom filter is never crossed.

The search starts with the active bloom filter for a particular element. If the required element is not found, the data is searched for in each element of the list filters in reverse order until it is found.
Note: This implementation appends a new bloom filter to the list. While searching, the list is reversed to maintain the reverse order.
The last method is __str__(). This prints the details of all the Bloom Filter objects maintained in the scalable bloom filter.
Finally, the file For Article/Bloom Filter—Part 4/test_scalable_bloom_filter.py has two test cases. The first test case checks the creation of a new bloom filter once the original bloom filter fills up. This “fill-up is done by setting the bits of the first bloom filter to 1.
The second test case adds many entries and creates new bloom filters when the current filter fills up.
I conclude the series with this article. I hope this has helped you in your journey to becoming a better software developer.
References
Did you enjoy this article? Please like it and share it with your friends.
If you have found this article helpful, please subscribe to read more articles.
Feel free to comment!!